
Serializability
Sections:
1. ACID properties
2. Schedules
3. Conflict serializability
3.1. Definition
3.2. Testing for conflict-serializability
1. ACID properties
We think of the database as executing transactions: Sequences of operations that are packaged together, that must be executed as a whole. We want the DBMS to provide four properties, called the ACID properties:
- A. Atomicity
Either all operations of the transaction complete, or none of them do. We're particularly want to avoid a transaction transaction that changes some of the entries that it wants but the DBMS fails before changing all of the entries.
- C. Consistency
The information in the database must be kept in a consistent state. This is largely the responsibility of the database administrator writing the queries, but the DBMS is also sometimes responsible: For example, if we have one table B that includes keys from another table A (such as bank account transactions that have account IDs referencing rows in a table of bank accounts), then the DBMS shouldn't allow deleting a row from A without deleting those rows from B referring to the account being deleted.
- I. Isolation
The transactions shouldn't have some complex interplay between each other: Conceptually, transactions should have the same effect as if they were done one a a time (though in fact the DBMS will need to do them concurrently).
- D. Durability
If the DBMS reports that it successfully completed a transaction, then all effects of that transaction should be permanent — even if the DBMS crashes (maybe due to a power outage) immediately after the transaction completes.
For the moment, we'll concentrate on isolation.
2. Schedules
Consider the following two transactions for a bank: The first is meant to deduct $100 from an account, while the second adds 0.5% interest to every account in the bank.
Transaction 1 Transaction 2 UPDATE accounts
SET balance = balance - 100
WHERE acct_id = 31414UPDATE accounts
SET balance = balance * 1.005
We'll want to talk about these transactions in the abstract. We'll summarize their interactions with the DBMS in the following form:
Transaction 1: r1(A), w1(A) Transaction 2: r2(A), w2(A), r2(B), w2(B)
The notation ri(X) indicates that transaction i reads the value for database element X, and ri(X) indicates that transaction i writes a new value for database element X. [We're being intentionally vague about what is meant by “database element.” You can think of it as being one row of a table, but a DBMS might think in terms of each individual cell in the table being an element, or it might think of the entire table as being an element. It might group several rows together into just one element.]
A schedule is some interleaving of the operations from the two transactions (without violating the order of operations within any individual transaction). So we can meaningfully ask: What is the outcome of the following order of operations:
Schedule S: r1(A), r2(A), w1(A), w2(A), r2(B), w2(B)
If account A starts with $200, and account B starts with $100, we can trace what would happen with Schedule S.
A B (initial:) 200.00 100.00 r1(A): r2(A): w1(A): 100.00 w2(A): 201.00 r2(B): w2(B): 100.50
Schedule S is very bad! (At least, it's bad if you're the bank!) We withdrew $100 from account A, but somehow the database has recorded that our account now holds $201.
What's a good schedule look like? Well, our ideal is a serial schedule, in which all operations by a transaction are grouped together. For our two transactions, there are only two ways to arrange their operations to get a serial schedule:
Serial schedule 1: r1(A), w1(A), r2(A), w2(A), r2(B), w2(B) Serial schedule 2: r2(A), w2(A), r2(B), w2(B), r1(A), w1(A)
In practice, a serial schedule isn't realistic, because it means we must wait for one transaction to complete before starting another. We would really prefer to interleave them — but we need to interleave the transactions so that they work the same as some serial schedule.
We call a schedule serializable if it has the same effect as some serial schedule regardless of the specific information in the database. That last clause “…regardless of the specific information…” comes from peculiarities that may arise based on precisely what the database contains. As an example, consider Schedule T, which has swapped the third and fourth operations from S:
Schedule T: r1(A), r2(A), w2(A), w1(A), r2(B), w2(B)
We can try tracing this on two different examples.
A is $100 initially A is $200 initially
A B (initial:) 100.00 100.00 r1(A): r2(A): w2(A): 100.50 w1(A): 0.00 r2(B): w2(B): 100.50
A B (initial:) 200.00 100.00 r1(A): r2(A): w2(A): 201.00 w1(A): 100.00 r2(B): w2(B): 100.50
Looking just at the first example, we see that the outcome is the same as the serial schedule where the withdrawal happens first and then the interest is credited. But that's just a peculiarity of the data, as revealed by the second example, where the final value of A can't be the consequence of either of the possible serial schedules.
So neither S nor T are serializable. What's a non-serial example of a serializable schedule? We could credit interest to A first, then withdraw the money, then credit interest to B:
Schedule U: r2(A), w2(A), r1(A), w1(A), r2(B), w2(B)
3. Conflict serializability
Our definition of serializability is a bit difficult to handle: How can we test for the same effect regardless of data? To come up with an answer, we'll create a stricter definition of serializability, called conflict-serializability.
3.1. Definition
First, though, we'll define conflict-equivalence: Two schedules are conflict-equivalent if one can be reached from the other through a series of swaps of adjacent operations, where no swap falls into one of the following patterns:
- the operations are by the same transaction
- the operations use the same database element, and at least one is a write
For example, Schedule U is conflict-equivalent to Serial Schedule 2, as shown by the following series of swaps.
Schedule U: r2(A), w2(A), r1(A), w1(A), r2(B), w2(B) swap w1(A) and r2(B): r2(A), w2(A), r1(A), r2(B), w1(A), w2(B) swap w1(A) and w2(B): r2(A), w2(A), r1(A), r2(B), w2(B), w1(A) swap r1(A) and r2(B): r2(A), w2(A), r2(B), r1(A), w2(B), w1(A) swap r1(A) and w2(B): r2(A), w2(A), r2(B), w2(B), r1(A), w1(A)
A schedule is conflict-serializable if it is conflict-equivalent to some serial schedule. We've just shown that Schedule U is conflict-serializable.
You may wonder: Are all serializable schedules conflict-serializable? As you might expect, though, the answer is no. Consider the following schedule for a set of three transactions.
w1(A), w2(A), w2(B), w1(B), w3(B)
We can perform no swaps to this: The first two operations are both on A and at least one is a write; the second and third operations are by the same transaction; the third and fourth are both on B at at least one is a write; and so are the fourth and fifth. So this schedule is not conflict-equivalent to anything else — and certainly not any serial schedules.
However, since nobody ever reads the values written by the w1(A), w2(B), and w1(B) operations, the schedule has the same outcome as the serial schedule:
w1(A), w1(B), w2(A), w2(B), w3(B)
3.2. Testing for conflict-serializability
Using the definition of conflict-serializability to show that a schedule is conflict-serializable is quite cumbersome. There's a much more efficient algorithm:
- Build a directed graph, with a vertex for each transaction.
- Go through each operation of the schedule.
- If the operation is of the form wi(X), find each subsequent operation in the schedule also operating on the same data element X by a different transaction: that is, anything of the form rj(X) or wj(X). For each such subsequent operation, add a directed edge in the graph from Ti to Tj.
- If the operation is of the form ri(X), find each subsequent write to the same data element X by a different transaction: that is, anything of the form wj(X). For each such subsequent write, add a directed edge in the graph from Ti to Tj.
- The schedule is conflict-serializable if and only if the resulting directed graph is acyclic. Moreover, we can perform a topological sort on the graph to discover the serial schedule to which the schedule is conflict-equivalent.
As an example, consider the following schedule:
w1(A), r2(A), w1(B), w3(C), r2(C), r4(B), w2(D), w4(E), r5(D), w5(E)
We start with an empty graph with five vertices labeled T1, T2, T3, T4, T5.
We go through each operation in the schedule:
w1(A): A is subsequently read by T2, so add edge T1 → T2 r2(A): no subsequent writes to A, so no new edges w1(B): B is subsequently read by T4, so add edge T1 → T4 w3(C): C is subsequently read by T2, so add edge T3 → T2 r2(C): no subsequent writes to C, so no new edges r4(B): no subsequent writes to B, so no new edges w2(D): C is subsequently read by T2, so add edge T3 → T2 w4(E): E is subsequently written by T5, so add edge T4 → T5 r5(D): no subsequent writes to D, so no new edges w5(E): no subsequent operations on E, so no new edges We end up with the following directed graph.
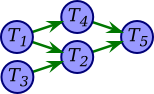
This graph has no cycles, so the original schedule must be serializable. Moreover, since one way to topologically sort the graph is T3–T1–T4–T2–T5, one serial schedule that is conflict-equivalent is
w3(C), w1(A), w1(B), r4(B), w4(E), r2(A), r2(C), w2(D), r5(D), w5(E)